This project started a long time before the fiber project but after I did some stuff with wireguard. While I had things setup on my various devices, I couldn’t quite get things to work for my wife and had issues/annoyances with shifting networks. Everyone’s been talking a storm about Tailscale but I’ve put it off because there was no self-hosted option…until recently…or at least recently in me finding it.
Headscale has been really easy to get up and running. They don’t like you to it in docker, but it works alright for my needs. I also ended up running another couple of DERP servers “closer to home” to reduce ping/lag.
The only headache I’ve had so far was that recently I started losing connection to things randomly and then it’d come back just as randomly. I eventually figured out that the cause was that one of the DERP server’s letsencrypt certificate was old. Restarting the docker image fixed that and I haven’t had any problems since.
I live in the middle of no where. The only ISP services I have access to is from a couple different WISPs and Starlink. The WISP’s have an edge in terms of pricing, being significantly cheaper than Starlink. Their download speeds aren’t too good being a quarter to half the download speed of Starlink but where they shine is that they are within spitting distance for upload. Because of that, there’s not too much reason to change providers.
Getting speedy fast internet was a dream…until recently when I started making headway in convincing a neighbor who (for some inexplicable reason) has fiber service to let me rent space for a point of presence. This took a while to do and in retrospect I think the reason was, he thought I just wanted to share his internet connection and not get my own.
So with that agreement in place, the hard stuff began.
What I thought would be a hard part was actually one of the easiest. I thought I’d have a tougher time talking with the fiber ISP and convincing them to sell me access for this. Turns out, they don’t really care as long as I’m not reselling the service.
What I thought was going to be the easy part, turned out to be the harder part!
Challenges
Limited access of pop/remotely manage the pop
Keep hardware to minimum at pop
Only 1 ethernet to the home pole
Graceful switchover
PoP Hardware
As I have limited access to the PoP and didn’t want to bother my neighbor when I needed to do a simple reboot or to talk to the radio for some reason. For that I needed some way to access the things from the driveway. To address this I decided to use a cheapo GL.inet Shadow that was laying around to give me a wifi AP for access. To be able to remotely power cycle things, I’m using Sonoff S31s flashed with Tasmota. These are super handy little things and I’m starting to use them all over the house for monitoring stuff or managing things like scent diffusors.
To segment power, management, and internet traffic, I’m using a Mikrotik CSS610-8G-2S+IN to VLAN off each network. If didn’t want a router onsite, at least not yet, because I wanted to keep that at home. One reason was because that’s something that can go really wrong and getting access to it physically could be problematic. The other reason is so I can have backup internet options without having to rely on the PtP radios to be working.
All the inside stuff sits nicely in a 6u wall mounted networking cabinet…except for the UPS and Shadow. I couldn’t get the UPS to fit with the switch in there and the Shadow is velcro’d to the outside to increase the wifi signal strength.
For radios I found a couple new in box Ubiquiti AF60-US’s that popped up on Ebay for a decent $200/each. I went with them because Linus Tech Tips did a video on the LR version with great success. I really wanted a 5Ghz backup link for those bad MN blizzards or summer rain and Wave-Pros were 3x the price. While the LR or Nano might have worked, they were still 1.5-2x the cost and the link was limited to 1.5Gbps (750/750 if maxing out the link).
Another radio I was seriously considering was the Tachyon Networks TNA-303x while using some old AirMAXs that were laying around as the backup link. I was really close to ordering some, but the AF60’s popped up and I couldn’t say no to the price.
I don’t off the top of my head know if other brands have it, but I like that Ubiquiti has a Bluetooth interface that can be talked with to do configuration on their hardware. This was really handy when I was in high places where I just needed to whip out my phone to do the aiming without having to have an entire network stack up and running first. (I had done the initial conf on the ground weeks before install.)
On the roof, my neighbor asked that I don’t put any holes in his roof. While putting a J-Pole on the side of the building might have worked, that both introduced some challenges for installation and it limited where I could put the radio. Instead I opted for a non-penetrating mast from EasyUp that would sit on his flat root. This made him really happy as it was something that could be removed easily and didn’t mar his building.
Home Front
My current ISPs radio is about 90m from the house and connected via a direct burial ethernet cable. While I could do a hard switchover by swapping radios, there’s no testing without interrupting the fam and not much going back easily if things go south. I’ve also put in some direct burial fiber that is really close to it so putting in another line wouldn’t be simple. The only feasible option left was to get my hands on some sort of outdoor switch that was managed and could do 802.3at PoE.
For this I settled on a TP-Link Omada SG2005P-PD along with a couple Ubiquiti INS-3AF-O-G to convert 802.3at to passive PoE for the existing radio and the AF60 I was planning on putting in. My only complaint against it is the webui is slow and it has high ping to itself.
Why TP-Link here and not Mikrotik’s new GEPR4? Because it doesn’t switch or that is, all traffic needs to go thru the uplink twice since each downstream port only can talk to the uplink port. While at the moment isn’t a problem since all the traffic will need to go into my home network anyway, it might not always be the case. I have a long term plan to add stuff to the Back 40 to monitor things like ditch water levels, watch wildlife, or see what’s going on beyond the tree line for weather. If I move the router to the PoP all this traffic would have to go thru the 1Gbps link twice if I used the GEPR4.
PtP Install
The fiber install was somewhere between 3 weeks out and 3 months, so I figured I’d best use that time to get the PtP up.
I started with the home end. I put the Omada in place, rewired things on the pole, and made sure the existing WISP still worked. It did and was like nothing ever happened. Putting the AF60 in place was a bit more of a challenge though. I should have know it when I bought it, but the AF60 doesn’t come with an aiming device! The AF60-LR apparently does, but not the AF60! I had to just eyeball the aim and hope I was close enough to at least get the 5Ghz radios to connect. This was really annoying that I couldn’t even find an ebay listing for a used aim tool.
For the PoP end, I ended up renting a scissor lift to haul the heavy things up to the roof. At first the plan was to just haul things one at a time up a ladder or pull them up with a rope, there was a problem though, I lacked a ladder that tall. Plus it seemed a bit dangerous keep going up and down all the time and with heavy things. A few trips up and down and all the hardware was up top.
To aim the radio, I took a UPS up too. As my luck had it, I had aimed the radios so well that I was able to get about a -65dBm 60GHz signal right out the gate! After some fiddling I was able to bring that down (up?) to the mid-50s. Bringing it closer to the expected strength required some fiddling at the home end afterwards. I might need to revisit the roof at some point, but I have a ~90% link potential so it’s not something I need to do soon.
From the Omada switch, I then had four vlans, one for each ISP, one for the far end power management, and the untagged/native for the ptp management. I went this route as it seems to be the best for simply connecting and troubleshooting the radio on the far end in case anything goes wrong.
This setup though causes the MTU to
Monitoring
As I’m not sure how well MN and this link distance fares for 60Ghz, I wanted to monitor stuff long term. For that I choose to put a Grafana and Prometheus setup in place. Besides the SNMP Exporter to monitor the radios, I also got the JSON Exporter too so I could monitor weather conditions and try to correlate that to signal strength and link speed. The JSON Exported took a bit of finagling to get working but between the logs and sparse documentation, it was working in short order.
Fiber Install Day
Everything went super well. I was really worried I had screwed something up, but the ISP techs got everything setup on their end. When they finally got the ONT provisioned, I saw my home router pick up a DHCP assigned address. Then I went home and changed the primary gateway to the fiber interface and IT WORKED!
The feels were like when my parents went from dialup to DSL.
So Far
So far this has been really interesting. We’ve had some really heavy rain days which have destroyed the 60GHz link. If my calculations are right, the rainfall was 2x that UISP design center’s precipitation calculator maximum. The 5GHz link though stayed up quite nicely and seemed to perform the best at 40MHz channel width. Speeds were even better than the old WISP service too. Not 1Gb speed, but still having ~75-100Mb was a nice thing to see.
A bit nitpicky, but you can’t run iperf on AF60s from the ssh/command line and get meaningful results. For me, I was getting about 1/3-1/4 the speeds the webui’s tests showed. You’ll need some device on the other end to do meaningful iperf tests. The jury is out if it’s a limitation of the radios (very well could be) or just a skill issue (also very likely).
The World of Tomorrow
For the future, I think I need to find radomes for the winter time. Posts on the Ubiquiti forums lean towards it being necessary for winter time snow. However, I’m not entirely certain now helpful it would be for one radio as it’s pointed away from the winter wind direction 99% of the time. It would suck to have to climb up on the roof during the winter time to deal with snow and ice accumulation though. So it might be a good idea to do it sometime before that. Ounce of prevention and all that.
Replacing the switch with a router at the PoP end to handle the ISP handoff and forwarding all traffic to the home router’s RFC1918 “WAN” address (for nat-pmp). Mostly this would be to make management of PoP assets easier and be able to access them thru a backup internet connection from home. Scratch that, I found out that I can have multiple devices on the WAN and each can request their own public IP thru DHCP. Plans are going to shift to put a just powerful enough router on the PoP end and use a VPN like Tailscale to manage things thru a backup internet connection at home or my cell.
Replacing the current masts with 10-20ft Rohn Self Supporting towers. For the PoP end, this would require some trenching and electrical work besides convincing the neighbor to be on board with it.
A backup internet. At the moment that’s my previous WISP. It’s kind of expensive for that purpose though. I’m thinking I might use my cell phone as a hotspot when I need to. The only issue I have with that at the moment is my office is in the basement and gets terrible signal. If I didn’t need my phone for MFA, I probably would just put it on an upper level. I’ve been reading up a bit on cell signal boosters which looks promising.
Gists
Tasmota
For flashing the Sonoff S31’s, I followed this guide by Aaron Cornelius. I highly recommend getting the clips he talks about. They made the task much much easier.
Here’s a template for setting up a S31s with Wi-Fi, auto power on after ~10s, & MQTT. Just replace the uppercase stuff with your stuff. This does all this conf in one go. If you’re not needing MQTT (I used it to connect it to my Home Assistant), it can be dropped.
The main things that make this work is the PowerOnState and PulseTime. The PowerOnState being set to 5 makes the default state of the switch to be on and the PulseTime sets the timeout for turning back on. I did things this way so that stuff should come back to a workable state if I turn the power off.
Importing MIBs into the SNMP Exporter is kind of a hassle. So I made this little script to combine my auths config with the MIB data compiled by the SNMP Generator. This does require the yq tool.
#!/bin/bash
docker run --rm \
-v "${PWD}/snmp-generator/generator.yml:/opt/generator.yml:ro" \
-v "${PWD}/snmp-generator/snmp.yml:/opt/snmp.yml" \
-v "${PWD}/mibs:/opt/mibs" \
prom/snmp-generator:latest \
generate --log.level=debug
#pick out one and preserve the tree.
yq eval-all '. as $item ireduce ({}; . * $item)' snmp-exporter/snmp.base.yml snmp-generator/snmp.yml > ./new_snmp.yml
I have a problem. I’ve wanted to get better Wi-Fi coverage in the far reaches of the yard and open up options for fixed wireless internet service. While better coverage would be a bit simpler with some ptp wireless and/or mesh Wi-Fi offerings, there was a lack of power in the places I wanted and needed to put nodes.
Enter my wife with a solution! Our barn/chicken coop hasn’t had power since an unfortunate water line break and the digger broke the power line. This hasn’t been a huge issue as we haven’t needed power out there until now. Now the Mrs. wants to have lighting in the barn for the winter as well as a camera; partly to watch her cute chickens and partly to keep an eye out for predators breaking in. A perfect opportunity and excuse! Since I’ll need a trencher to bury the power line deep enough, I might as well bury some network cables too!
What kind of networking though? Ethernet is pretty simple and I have crimping tools. The downside though is that it’s kind of limited in top speeds. I maybe could get 10Gb going, but that’s not a given because of the distances and 10Gb Ethernet is kind of expensive anyway.
Fiber though has some things going for it. First is the obvious in that we have longer distance and top speeds. Though I only went for OS2 fiber and so I’m limited to 10Gb (20Gb LAGed if I used BiDi modules). Mainly because I didn’t shop around enough to find direct burial MMF for an decent price. It’s likely way more than I’ll need for PoE cameras and extending Wi-Fi and I doubt any internet service I could get would exceed that anyway.
For trenching I went with a Ditch Witch from a local rental shop. I would not really recommend that. Partly because the one I got was really finicky and the neutral was basically non-existent. I don’t know if it was inherent to the machine or just the age/maintenance. But whatever the reason, this made alignment really difficult and basically impossible. When/if I need to bury more cabling, I think I might go with a backhoe instead if I have to do any sharp angles or multiple buildings or go with a EZ Trench.
While I was at it, I also wired up the workshop. There’s nothing in there yet, but due to the walls it has poor wifi signal so its definitely high up on the list of upgrades to come. While I’m not sure what else might get put out there besides maybe wifi AP and camera, I am toying with the idea of putting a phone/intercom in there (and the barn) to make quickly communicating across the yard easier.
This project was very fun and surprisingly quick. The part that took the most time was finding cabling and waiting on delivery of the materials. Trenching took only a couple hours even with all the issues I was having with the machine.
One thing I’ll probably do differently next time now that I know it has long lead times is order custom length multi-fiber cables from someplace like fs.com. I didn’t this time as when I went to order, it was going to take months to get the cables and push the install from summer into late fall.
and it got me itching for something like them for serial consoles. And by something similar, I mean cheap for what it is and hits 80% of the needs for connecting to a serial console over a network. Surprisingly this is a very expensive thing. While I might be searching for the wrong tech, the results I am finding are comically expensive. We’re talking at least $100 for a single port model. I’ve seen some older models go for $25 on Ebay, but they are so old the manufacturer either doesn’t exist or they’ve been sold off so many times, the current company hasn’t any idea it was made by them.
My requirements are that it should be PoE, can be assigned an address via DHCP, and simple telnet that just passes thru the console it’s connected to. Simple yes? No.
This could be kit bashed together with a Raspberry Pi with a USB to serial adaptor. The problem with those options is that by the time you have everything, it’s almost as much as those other single port terminal servers. While you’ll have more functionality in them, in the terms of price, you might as well go with the other stuff because otherwise you’ll go mad keeping things running.
I started this project thinking I’d need to get my hands on an ESP32 board, write up a sketch to do simple a console/telnet proxy in order to get my vision realized. Though I did do that…terribly it turns out that it’s about as cost effective to kit bash together a cheap travel router, cheap usb to console and optionally a PoE splitter or usb hub. Even with adding a PoE splitter, you’re looking at ~$50 outlay. Heck, it’s even more secure since you could ssh into the router instead of being limited to telnet. Plus the usb hub is a killer feature multiplier and makes this an even more attractive route when dealing with multiple serial consoles.
Though the experiment was a failure, I did get to learn some about ESP32 and how to use them. So I guess it was a win after all.
A few weeks ago I decided to explore High Availability for my home network for routing. Initially I thought I’d put a couple Mikrotik’s between my Opnsense and my ISP’s hardware. However after thinking about it, decided to just run a secondary Opnsense as a VM since the ISP hands out CGNAT addresses to all devices connected to their hardware. It turns out, the VM is even faster than my hardware router, so I might even migrate the primary to be virtualized too.
First I thought it would be pretty simple, just turn on HA on the primary router and be done with it it. No, it’s not that simple…it’s never that simple. Because of the way I have my IPv6 setup, the VPN configuration from the primary gets copied over and goes connects from the secondary as well. As far as I can tell there’s no way to prevent this. So I whipped out my .plan file and went to work.
The first thing I did was create a new VPN tunnel for the second machine. Next I created new VXLANs between the routers and the ipv6 cloud endpoint and bridged them together so they all act as if they are on the same network. The ipv6 cloud node then routes traffic to a CARP address that’s shared with the routers.
For ipv4, I changed the primary router’s IP address and added the old default gateway address as a CARP address.
Individual ipv4/ipv6 TCP connections fail, for example, my SSH sessions disconnect, but otherwise the rest of the family doesn’t notice a thing now when I failover the routers.
This all really came in handy not to long ago when my physical router froze up while I was away. No one noticed that it had happened and cheerfully went along doing their school, play, and memeing. Once I was back home, I rebooted the hardware and no one noticed anything.
Other things I noticed…
When first bridging the VXLANs together, pinging the other router would go thru the ipv6 cloud node. Fixing this required enabling STP in netplan, setting the router’s port id lower, and adding the vxlan interfaces as auto edge. Big note here, enabling STP for an interface in netplan also makes updating the interface impossible. The only way I found to enable updates to the netplan is to reboot the machine.
OPNSense will sync things like firewall rules, but the interfaces must have the same “internal identifier”. The easiest way I found to ensure this is to download a backup of the configuration and rename the interfaces. Note that this is not the same as the name you give an interface. Internal interface for names follow the pattern “optN” where N is the +1 of the last interface created. To simplify things, I changed the internal names to match the name I had given the port (eg vxlan99, br1, etc). This really tripped me up at first as the rules were being applied to the wrong interfaces. This made syncing the HA stuff a nightmare as the link kept failing after because the firewall suddenly stopped accepting traffic from the other router on the syncing interface.
Things I wish were different
As alluded to earlier, I thought OPNSense HA would just simply sync settings and the secondary would only be enabled if the primary failed. That is not the case and I’m not sure why they let you sync things that would have to be specific to each router like vpn profiles or interface settings. I could be missing something though.
It would be nice to have some ability to map things to stuff on the other side, have a finer grain control of what can get synced, or some sort of ability to change a setting for the secondary. For example CARP settings can be synced…but what’s the point if the settings are the same and each node is taking over the IP all the time? It would be nice to be able to have some settings like the advertisement interval be changed or automatically assigned so that the secondary node will always be second.
I sit behind a IPv4 only CGNAT which is very annoying for self-hosting stuff or using TunnelBroker for IPv6. Sure, there’s options like Cloudflare’s Tunnel for the self-hosted service stuff, but that’s a huge ask on the trust. It also doesn’t address the lower level networking needed for 6in4/6to4/6rd/etc.
An important and something I initially overlooked was choosing a VPS host that has low latency with the TB service. The lower ping time from the VPS to TB, the lower impact on your IPv6 internet experience. For example, if your ping time from your home to VPS is 50ms and the ping time from the VPS to TB is 30, you’re going to have a total IPv6 ping of at least 80ms from your home.
I like Wireguard and I already have a v4 Wireguard network up and running, so I’m using that as the starting point. I have tried using Wireguard for all traffic before from my router without much success (likely a skill issue). Plus I find the whole “allowed-ips” a huge hassle. So why not just overlay a VXLAN? That way, I could treat the thing like a direct link and route any traffic over it without needing to worry about those dang “allowed-ips” settings.
#/etc/netplan/100-muhplan.yml
network:
version: 2
tunnels:
# he-ipv6 configuration is provided by tunnel broker
# routes: is changed slightly to use a custom routing table.
# routing-policy is added to do source based routing so we don't interfere with host's own ipv6 connection
he-ipv6:
mode: sit
remote: x.x.x.x
local: y.y.y.y
addresses:
- dead:beef:1::2 # this endpoint's ipv6 address
routes:
- to: default
via: dead:beef:1::1 #the other end of the tunnel's ipv6 address
table: 205 #chose any id you want, doesn't really matter as long as it's not used.
on-link: True
routing-policy:
- from: dead:beef:1::2/128 #same as this endpoint
table: 205
- from: dead:beef:2::/64 # the routed /64 network.
table: 205
- from: dead:beef:3::/48 # the routed /48 if you choose to use it.
table: 205
- from: dead:beef:3::/48 # put /48 to /48 traffic into the main table (or whatever table you want)
to: dead:beef:3::/4
table: 254
priority: 10 #high priority to keep it "above" the others.
# setup a simple vxlan
# lets us skip the routing/firewall nightmare that wireguard can add to this mess
vxlan101:
mode: vxlan
id: 101
local: a.a.a.1 #local wg address
remote: a.a.a.2 #remote wg address (home router)
port: 4789
bridges:
vxbr0:
interfaces: [vxlan101]
addresses:
- dead:beef:2::1/64 #could be anything ipv6, but for mine I used the routed /64 network.
routes:
- to: dead:beef:3::/48
via: dead:beef:2::2 # home router
on-link: true
Figuring out where things were failing was tricky as I wasn’t sure if the issue was with my home firewall or my VPS. Pings to and from the VPS were working, but nothing going thru it worked. I thought I had the right ip6table rules in place but evidently I did not. Hmm
Reviewing my steps, I found I had forgotten all about net.ipv6.conf.all.forwarding! A quick sysctl got it working and adding a conf file to /etc/sysctl.d/ to make it survive reboots.
Ping traffic was flowing both ways, but trying to visit an v6 website like ip6.me would fail. Grabbed a copy of tshark and watched the traffic. It showed me the issue was with the VPS. Thankfully UFW has some logging that helped track down the issue was indeed with ip6tables and the output helped me write the necessary rules to allow traffic thru.
Which allowed the traffic to flow and and out of the home network. However reboots are a problem. Thankfully UFW allows us to easily add the above rules so they survive a reboot.
ufw route allow in on he-ipv6 to dead:beef:3::/48
ufw route allow out on he-ipv6 from dead:beef:3::/48
#these don't seem to be needed? Default UFW firewall has ESTABLISHED,RELATED set.
Of course after I started setting the static addresses and updating my local DNS, I realized I should have done a ULA prefix and used NPTv6 to make future migrations easier.
Improvements?
I’d like to revisit using Wireguard without vxlans. It is another layer that can go wrong and may be something that isn’t needed and cuts down the maximum MTU.
If I ever got a second home internet connection, I’d like to aggregate traffic so that my effective home internet speed improves.
I’ve been finding that running DNS on my “NAS” isn’t the best of ideas and I’d like to have a “highly available” DNS system. Nothing’s quite worse than getting a call from the Mrs complaining that the internet isn’t working while you’re in the middle of a system update or because the cat stepped on a power switch. (Racking everything is another long term goal.)
I have been using Technitium’s DNS Server for my network. It feels light and snappy, lets me do unholy things with DNS, has really good filtering abilities. The problem I have with it though is there is no ability to configure one and it’s peers update from that too. There’s no replication going on (though according the github, it’s in the works).
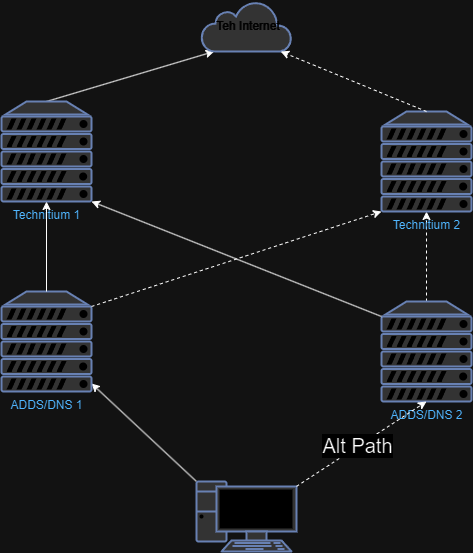
Which is why I like ADDS DNS, records are replicated to all nodes and it just works(tm). So I light up some Server Cores and setup my own little forest.
The resulting DNS structure is very simple. On each of my Proxmox servers, I run a copy of Technitium and a ADDS/DNS server. The ADDS/DNS is pointed at each of the Technitium for forward lookups which in turn look to Quad9 and Google (I know I know, but they seem to run a pretty decent DNS resolver) for their own forward lookups.
Going forward, I’d like to get the DHCP integrated into the DNS servers so hostnames are updated. My network is fairly small so manually adding records for the important things isn’t too much of a hassle. If I had a Proxmox cluster and Ceph pool setup, I’d probably have forgone this, but I don’t have either….yet.
Post draft update
We lost power this last week and the main Proxmox server is out of action which means that I’ve lost half my DNS servers now. Except for the little hiccup in that I had forgotten to add Technitium2 to the forwarding list on ADDS/DSN2, this thing has worked perfectly.
With the recent news of OpenSSH getting haxed…again, I was wondering if it would be possible to marry Wireguard’s not-so-chatty traffic model with ssh.
Then it hit me…why not just only listen on (or allow traffic from) Wireguard interfaces? So I whipped up a test Ubuntu 24 instance and starting banging rocks together.
First, lets get Wireguard installed.
$ sudo apt install -y wireguard wireguard-tools
Second, lets make a new Wireguard conf for the server and ourselves.
Third, lets enable the service, add a firewall rule to allow SSH traffic on our new interface, bring up the interface, and test the port.
$ sudo systemctl enable wg-quick@wgsshd0.service
$ sudo ufw allow in on wgsshd0 to any port 22
$ sudo wg-quick up wgssh0
$ sudo screen -S testing bash -c "ufw delete allow 22/tcp; sleep 120; ufw allow 22/tcp"
Now let’s test it from another machine.
$ ssh abc@myserver.exmaple.com # should fail.
$ ssh abc@[fd80:892b:9b39::1] # should succeed.
Finally, if everything works delete any other SSH port rules you may have.
Final Thoughts
Probably the biggest issue I can see is that this requires another service to be running before remote management of the machine is possible. Though with most popular hosts have a feature that lets you access the console thru other means. So this might be a none issue for most. Might be prudent to still have some firewall rules letting thru traffic from a limited subset of addresses to the sshd on the server’s pubic IP address.
Second biggest would be that every admin would need a Wireguard interface setup on every machine they use. While we’d need to get their ssh keys configured, it’s another thing to keep track of.